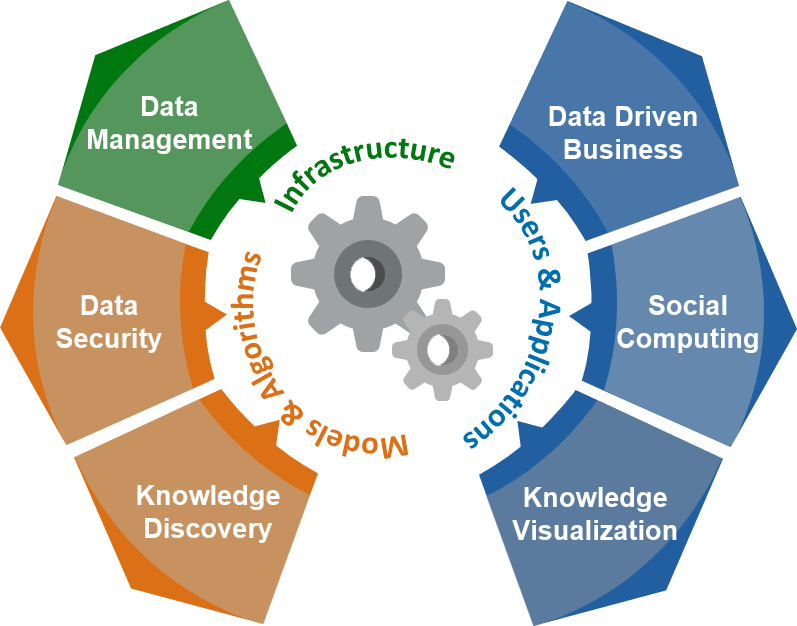
Our research programme aims at contributing to three main research objectives: The development of privacy-preserving data-driven AI, making AI explainable and verifiable for analysts and empowering end users in their interaction with AI. To reach these goals all reasearch areas at the Know-Center work together.
Research areas within the DDAI Comet Module.
Funding
The project is funded for four years and started with January 2020.
The DDAI module is part of the Competence Centers for Excellent Technologies Programme (COMET) funded by the Austrian Federal Ministry for Transport, Innovation and Technology (BMVIT), the Austrian Federal Ministry for Digital and Economic Affairs (BMDW), the Austrian Research Promotion Agency (FFG), the province of Styria (SFG) and partners from industry and academia (see our network). The overall budget of the module is 4 Mio. Euro.
Project Lead
Andreas Trügler
+43-316-873-30895
Cryptography
Modern cryptographic methods allow computation on encrypted data, i.e. without giving up any privacy we can still leverage machine learning evaluations and data analytics. In the DDAI module we combine cryptographic techniques with machine learning, here are some details about such methods.
Homomorphic Encryption
With homomorphic methods you can send your encrypted data to another party which can perform calculations without knowing the actual content of the data. You get back the encrypted results and never have to give up any privacy. This way you can securely outsource computation and analysis of data while enjoying full cryptographic guarantees.
Secure machine learning as a service would be a typical application of homomorphic encryption, see our project results for other use cases.
Multi-Party Computation
If you have a public machine learning model and private data, you can apply collaborative learning based on multiparty computation to securely share the data and jointly compute the model. No party can recover any of the private data sets.
Another option would be private classification, where both model (known to the server) and data (known to the client) are private. With mutliparty computation protocols you can still perform calculations without revealing model or data to the other party.
Zero Knowledge Protocols
How can you prove to someone that you know a secret without revealing itself or any information about it? That’s exactly what zero knowledge is about and the corresponding protocols can be applied to authentication systems or blockchain problems.
An easy to read and popular introduction about zero knowledge can be found here.
Besides encryption based approaches there are also several machine learning techniques available that already intrinsically preserve privacy and allow secure data evaluations. Federated learning and transfer learning applied to private data are two of them.
Federated learning
This method allows to train a global model over heterogeneous data sets on different computing nodes. No actual data is exchanged, only the parameters of the model.
Federated learning requires a lot of communication between the involved nodes, developing an efficient data management framework is therefore essential.
Transfer learning
Training a model on one dataset and then applying the pretrained version to similar or somehow related data usually increases efficiency, performance and accuracy of the model. It also allows to deal with data sets that are too small for adequate machine learning approaches, thus it can be used to evaluate small private data sets with models pretrained on public data.
A drawback of this method is that it does not allow to combine different private data sets, but it can also be linked with cryptographic methods to overcome this problem.
Privacy-aware recommendations
Providing personalized recommendations to users typically requires the processing of personal user data, which could impose privacy risks. To overcome this, the amount of personal user data could be reduced by using machine learning techniques such as meta learning. Additionally, privacy-preserving technologies such as differential privacy could be integrated into the recommendation process to significantly decrease the risk of private data disclosure. Closely related to these topics are data sparsity issues such as the cold-start problem, to which low-dimensional data representaiton methods such as graph embeddings or graph neural networks could be applied.
Modern machine learning algorithms are becoming more and more complex and quite often it is very difficult or even impossible to follow their decision process. Even though black-box models might excel with their extraordinary accuracy, having a black box instead of an interpretable model can become a serious drawback for industrial or scientific applications, due to the difficulty of explaining why a certain decision has been made.
Interpretability methods, such as Layer-wise Relevance Propagation (LRP), offer a way of opening the black box by highlighting which parts of the input contribute the most to a decision. In the above example it can be seen that a model, which was trained to discern cats and dogs, looks at the shape of a cats head and at its eyes to come to the conclusion that it is indeed a cat.
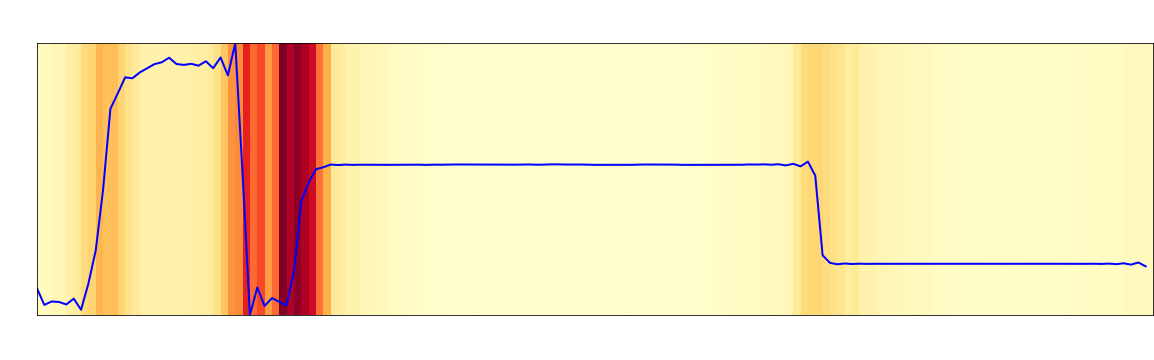
These interpretability methods are not exclusive to images, and can be applied to any kind of data, such as time series. The above time series example was classified as an anomaly during the production process of silicon wafers and with LRP the exact time steps can be identified that were crucial for the classification as an anomaly. Another application area that typically lacks of interpretability are decisions and results derived by graph-based machine learning and recommendation systems. By studying and using social concepts such as homophily, a better understanding of complex, graph-based algorithms can be derived.
In the DDAI module we tackle such problems with visual analytics and new methods from the field of explainable AI and bring it together with our privacy-preserving approaches (see cryptography and private machine learning).